Thoughts on Infrastructure

I am in Tokyo and live in a roughly 7sqm room with an AC that can either HEAT or COOL. Neither of the options is satisfying, and the air inside the room is poor. So I sit in the friendly cafe nearby, working away and enjoying life.
6 weeks ago, we (and with ‘we’, I mean ‘I’) migrated our cloud infrastructure from Google Cloud to AWS, and it was one of the hardest things I ever did concerning neural frames. Everything broke down, and there were days and days of server errors, working 18hour days, waking up at 5am bathed in server errors, and complaints. Anyway, I was able to finish it, most customers were patient and luckily Liz, our brilliant customer support agent, kept the angry customers away from me.
I was, however, so traumatized of this, that I postponed transferring the storage. We are talking about bringing 80TB of data, most of which in the form of tiny images making up millions and millions of files. AWS offers a data transfer solution, which they advertised to me right away. I tried it a couple of times and unfortunately one cannot transfer more than 25 million files with it, and apparently we have more (god knows how many).
I requested an increase in this limit, but they said they could not. Fun fact: You need to beg them to spend money at AWS (and, I guess, the other cloud providers, too). Everything needs to be requested, and everything needs reasons and time. Anyway, I wasn’t allowed to transfer more than 25 million files, and the workarounds they came up with were not less work than writing a python script myself.
I did however discover an open-source data transfer tool, called rclone and it seems to work! It is working my way through the storage one Americano at a time and if current speed holds up it will be done in 10 days.

The tool is great. If i’d known how easy and great it was I wouldn’t have wasted my time with trying to make the other solutions work.
Storage is actually a giant mess that I postpone to think about myself. Every rendered frame is a file in the storage, and for SDXL models those can already make up 1mb. One single 3 minute render, therefore, already consists of 4.5 GB of image data. How do people solve this? Compressing the files doesn’t seem right. Maybe I should delete them after a while, but that would also not be fair.
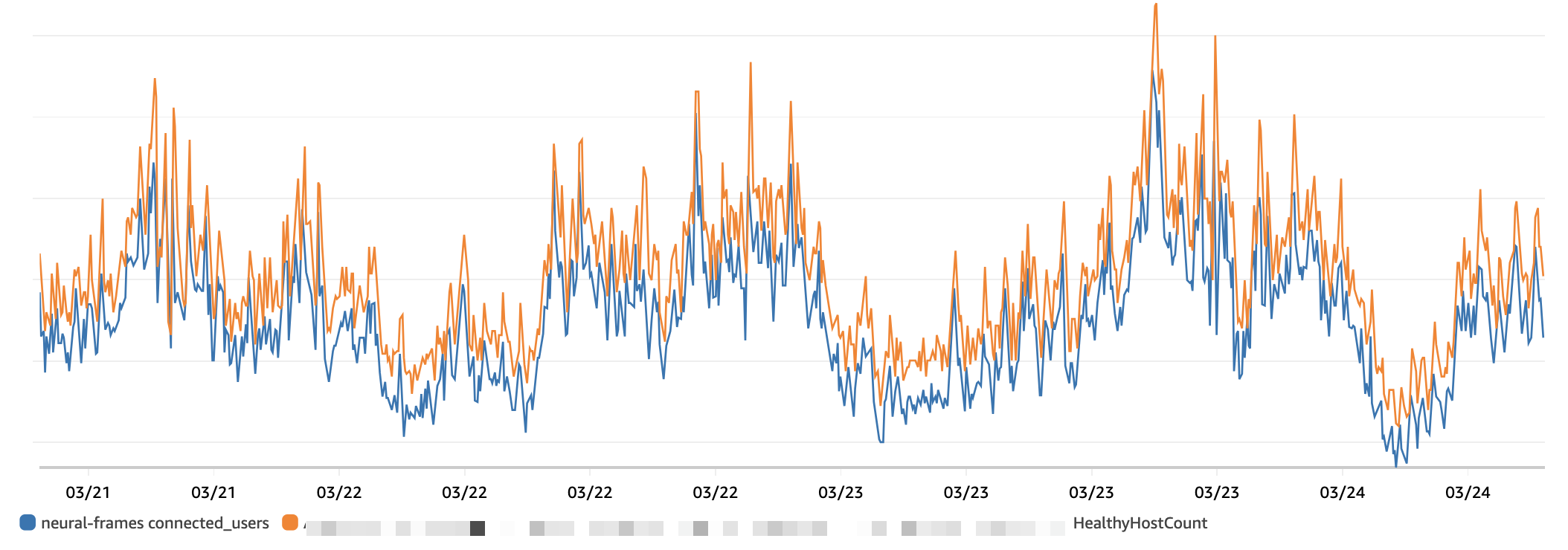
On that note: I also wrote an autoscaler and load balancer myself on the new cloud provider. Below you see in orange the number of available GPUs and in blue the number of connected users. The fact that the orange curve is always slightly above the blue is a good thing and means that there’s always a GPU available for users. I am trying to decrease the distance between the two to optimize costs.
I think if I could summarize this post, it would be: There is a lot of infrastructure work and optimization going on under the hood and I am still solving it by myself, although probably not for much longer. I do enjoy this kind of work but it is more fruitful to think about marketing or product stuff.
Happy Sunday!