Building something by myself
The largest rushes of adrenaline I've had in my professional life, always came when I was programming. During my PhD days, I was an experimentalist on paper, who worked in the lab. But when I started trying to simulate the microscopic dynamics that I have been measuring, I became absolutely obsessed with getting the code to produce meaningful stuff at a reasonable speed (and succeeded!).
From then on, it was clear to me that I wanted to do more in this direction. It was also during a new hype around artificial neural networks. The then recently published "Attention is all you need" paper introduced the groundbreaking transformer neural network architecture and has been cited in only 5 years 3x more often than the seminal paper by Watson and Crick in which they proposed DNAs' double-helix structure.
So it was a good time for me to dive into this topic further and more obsessions followed. I tried to predict movement on the stock market (and failed), I set up an automated camera on my balcony that filmed the crows that visited us, including a twitter bot to post the resulting videos, and programmed all kinds of cool stuff at OQmented.
Generative AI and me
After Entrepreneur First (see my previous blog post), I was deeply motivated to build something again. There's a giant hype in the field of generative AI currently. New neural networks can produce images and text from input text (see ChatGPT and Dall-E). Particularly, the text-to-image thing has been fascinating to me. There's a method called Dreambooth where you can show these neural networks 10-20 images of yourself, fine-tune the model for half an hour, and then it will understand who you are and can depict you in a multitude of scenarios. For instance, may I present, myself as a rock sculpture in the style of Michelangelo.

From Images to Videos
These models can not only produce images from text but also images from images. Basically, you one can feed in an image and a text prompt, and it will create a new image out of that. One interesting use case of this is to pimp children's drawings.
Now one can go a step further and wrap this process into a loop. The model produces an image from a text prompt, this image is fed again into the model, of which the result is fed again into the model. This creates a series of frames, i.e., a video. One can further play tricks on the intermediate images, zoom in slightly, or tilt the images and thus produce super cool effects, that have been going viral ever since the release of the open-source text-to-image model stable diffusion. I used this approach for some animations myself and - although I really don't see myself as such a visual person - it felt immensely powerful to create something new just with the help of some text prompts.
One thing stuck out to me. Although there is really no intrinsic complexity in creating these videos (once the model exists, that is), the tools available for doing so, are powerful but tedious and complicated. Built by coders for coders. You need to type things in exactly the right, cumbersum syntax. You can almost not pause the video creation. If you manage, it is annoying to continue it. The list goes on. Thus, I arrived at the conclusion that I wanted to build such an easy-to-use tool by myself, for myself. I heard many times that it is best to solve one's own problems. Here I was with a problem. A cool problem.
Building
Six very intense weeks followed. I was lacking a lot of skills to pull this off. I feel at home with Python but all the other stuff I knew very little about. I built the website with React and was an absolute beginner in it, I set up a database without knowing what I was doing, and I spend way too many hours setting up the servers on AWS with appropriate load balancing and autoscaling - things I didn't even know I needed. Luckily, I had some credits for AWS business support and spend four hours over two sessions with the same AWS support engineer from US' Westcoast who explained carefully what I would need and helped me set it up.

Honestly, it was an intense experience and not very sustainable. I went down a six-week-long rabbit hole where I did nothing else except work on this and sports. The days just didn't end. It is so incredibly much work and I kept having ideas when I wanted to sleep. There were nights in which I slept four hours although I was lying in bed for eight or so. Not because I was worried but because I was excited. Again, not very sustainable, definitely would need to do something about it in the long run, but also: pretty fun.

Well, here I am now. I deployed the first version a week ago or so, it looks really shitty on a lot of devices, everybody keeps telling me how bad the UI/UX is (and they are probably right) and yet, it is still a product that is fun to use. I made the first money on the internet, six people paid for the site. For the first three payments, I had a bug in the payment process and people paid but didn't receive any credits. Kind of embarrassing but naturally, I reimbursed them later manually. And people understand that I'm alone on this.
I went mini-viral on Reddit (they deleted the post for some reason) and on HackerNews. The servers kept breaking and at some point I was having a screen with eight terminals open to monitor and keep them alive. Also, not particularly sustainable, but also quite exciting.
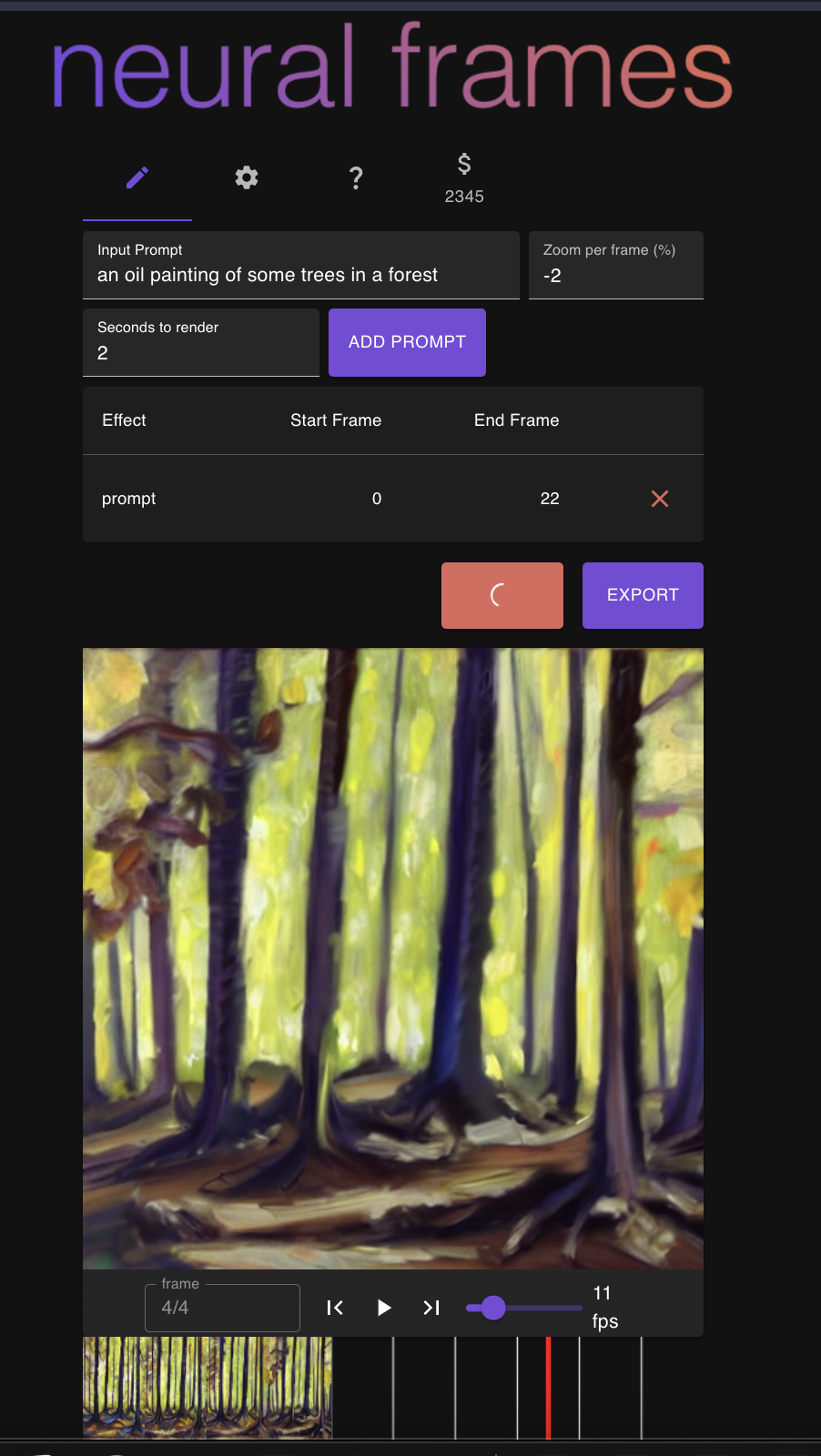
Let's see how this project progresses. The site had something like 7000 visitors within a week and this is a huge success for me. I think one can say, the idea is validated. To keep this going, I would need to find a way to monetize it better and I am thinking about how to do that. If you have any ideas, feel free to reach out!
Anyways, I think 2023 is off to a good start. I am looking forward to building more projects like this.
Follow neuralframes on Twitter if you wanna see some of the things that people are building on the site, and/or follow me on twitter, to see what I am up to and thinking about. And of course, got on https://www.neuralframes.com to check out the product.